
Hadoop:
- Apache'inin açık kaynaklı bir kütüphanesidir.
- İşlem hacmi büyük olan verileri depolamak ve analiz etmek için kullanılır
- Java dili ile yazılmıştır.
- Sıradan sunuculardan(commodit hardware) oluşan küme(cluster) üzerinde büyük verileri işlemeye yarar.
- HDFS, Hadoop Common, Hadoop Yarn ve Hadoop MapReduce bileşenleri tarafından oluşan bir yazılımdır.
Hadoop'un Modülleri

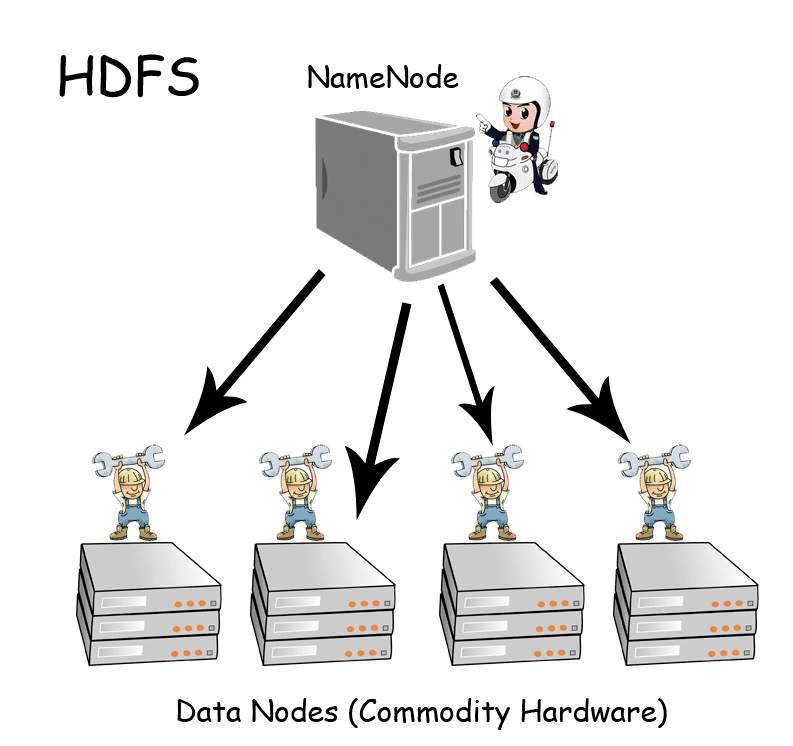
- HDFS(Hadoop Distributed File System)(Storage Layer): Hadoop cluster'larındaki verilere yüksek performanslı erişim sağlalayan dağıtılmış bir dosya sistemidir. HDFS, master/slave mimarisi kullanır. Master, dosya sistemin metadata'sını yöneten tek bir NameNode'dan oluşur. Gerçek data'yı depolayan bir veya birden fazla slave, DataNodes. HDFS alanında bir dosya, birkaç bloğa bölünür ve blok'lar bir DataNode kümesinde depolanır. NameNode, blokların DataNode'lara eşleşmesini belirler. DataNode, dosya sistemi ile okuma ve yazma işlemlerini yapar. Ayrıca, NameNode'lar tarafından verilen talimatlara göre blok oluşturma, silme ve replikasyon konuları ile de ilgilenir. HDFS, diğer bir dosya sistemi gibi bir shell komutu kullanır ve dosya sistemi ile etkileşim sağlamak için komutlar listesi mevcuttur.
- Hadoop Yarn(Yet Another Resource Negotiator): Verileri tutan kümedeki işleri planlanlamak ve kaynak yönetimi sağlamak için bir yapı sağlar.
- Hadoop MapReduce (Processing and Computation Layer): HDFS üzerindeki büyük verileri işlemek için kullanılan bir yöntemdir. İstediğinizi verileri filtrelemek için kullanılan Map fonksiyonu ve verilerden sonuç elde etmenizi sağlayan Reduce fonksiyonlarında oluşan program yazıldıktan sonra Hadoop üzerinde çalıştırılır. Hadoop Map ve Reduce'lerden oluşan iş parçacıklarını küme üzerinde dağıtarak aynı anda işlenmesini ve bu işler sonucunda oluşan verileri tekrar bir araya getirilmesinde sorumludur.

MapReduce terimi, aslında Hadoop programlarını gerçekleştirdiği aşağıdaki 2 farklı task'ı ifade eder.
- Map Task: İnput veriyi alır ve bir veri kümesine dönüştürür.

- Reduce Task:Bu task'ta, map task çıktısı girdi olarak alınır. Bu veri tuple(row)'larını daha küçük bir tuple grubunda birleştirir. Reduce task, her zaman, map task'ından sonra yapılır.

Client Machine: Ne NameNode ne de DataNode'tur. Client machine üzerinde Hadoop yüklü olan bir makinedir. MapReduce işlerini submit(göndermek) etmek ve tamamlandıktan sonra görüntülemek.
JobTracker, yazılan MapReduce programının cluster üzerinde çalıştırılmasından sorumludur. Ayrıca dağıtılan iş parçacıklarının çalıştırılması sırasında oluşabilecek herhangi bir problemde o iş parçacığını sonlandırılması ya da yeniden başlatılmasından sorumludur. TaskTracker, DataNode'ların bulunduğu sunucuda çalışır ve JobTracker'dan tamamlamak üzere iş talep eder. JobTracker, NameNode'un yardımıyla DataNode'un local diskindeki veriye göre en uygun Map işini TaskTracker'a verir. Bu şekilde verilen iş parçacıkları tamamlanır ve sonuç çıktısı yine HDFS üzerinde bir dosya olarak yazılarak program sonlanır.
- Hadoop Common: Bazı modüllerin Hadoop'a erişebilmesi için gerekli olan kütüphaneleri sağlar. Mesela Hive yada HBase, HDFS'e erişmek için bu kütüphaneleri kullanılır. Bu java kütüphanesi Hadoop'u başlatmak için kullanılır. Cluster'a veri yüklemekle sorumludur.
Hadoop Ecosystem

- Oozie:Bütün işleri shcedule etmek için kullanılan bir tool'dur.
- Sqoop:Klasik veritabanı ile HDFS arasında toplu veri transferi yapmayı sağlayan bir tool'dur.

- Zookeeper:İşlerin sürekli çalışır halde kalmasını sağlayan bir takip sistemidir.
- Oozie:Bütün işleri schedule etmek için kullanılan bir tool'dur.

- HBase:Dağıtık temelli kolon bazlı bir veritabanıdır.
- Hive:Dağıtık yapılı bir veri ambarıdır. Sql benzeri bir dil sağlar.
- Pig:Veri akışını kontrol eden ve büyük boyutlu verilerde işlem yapmayı kolaylaştıran bir tool'dur. HDFS ve MapReduce cluster'larında çalışır.
- MapReduce:Yukarıda anlatılmıştır.
- HDFS:Yukarıda anlatılmıştır.
- Flume:Hadoop'a aktarılacak dosyaların(log datası, ftp dataları, twitter datası vs) toplanması ve aggregate edilmesi ve taşınmasını sağlayan bir java uygulamasıdır. Bu java uygulamasına'da agent denilmektedir.


0 yorum:
Yorum Gönder